Executive summary:
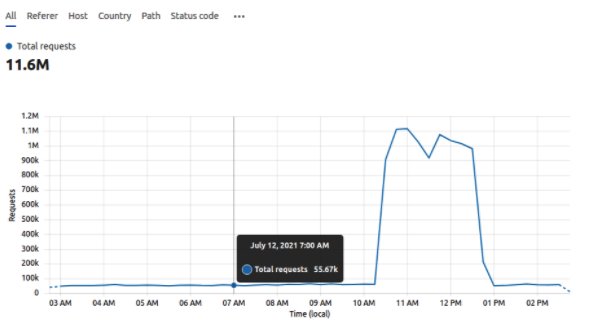
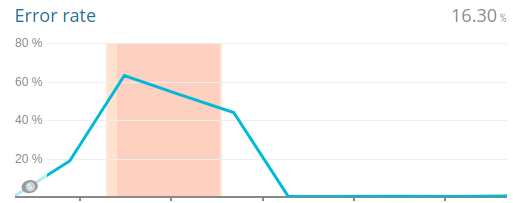
For the period between 12th and 29th of April 2019 several Planet4 websites experienced outage by having first their administration pages and later their public pages become unavailable. This was caused by an NFS filesystem which was attached to the PHP pods to persist wordfence firewall rules, logs and configuration. During that period 11 out of the 31 live websites experienced problems, and occasionally became unavailable.
Over the course of the next 17 days the ops team was investigating what was the cause of the issue, developing and testing theories, until the real cause was found during the weekend of 28th/29th of April and a fix was applied. During this period a methodology was fine-tuned to identify sites that were about to fail, and restart their resources in order to have minimum downtime.
Detailed report:
On Friday 12th of April an outage was reported on the international site. The outage was reported as front/back end, but initial investigation showed that for non-logged in users the front end was still available (served by cache). Efforts to rebuild/redeploy the website failed to fix the issue. A little later the front end also became unavailable, so we attempted to delete the helm deployment and recreate it, which seemed to fix the issue.
During the weekend that followed, two more sites (Chile and India) presented the problem, including the front end pages being unavailable until someone did a recreation of the whole helm deployment. (And thus the two big front end outages from the list below).
Since Monday 15th of April the Ray started investigating the issue. Logs were not showing anything useful so various theories started being forming and being tested in order to identify the cause of the problem.
- PHP 7.3
- Kubernetes node-pool version upgrades
- Kubernetes liveness and readiness health-check probe configuration and outstanding bugs
- PHP 7.2
- The container OS upgrade from Ubuntu xenial to bionic
- Support service upgrades (Redis, Consul etc)
- wp-cli incompatibilities
- Outstanding bugs in Kubernetes
For each one of those to be tested a new configuration was being rolled out with the relevant changes.
At the same time a methodology for identifying sites that had started crashing was established, and extra monitoring tools (to identify when backend was unavailable which was an indicator) were setup and started getting used. This resulted in identifying sites that were about to fail early on, and doing the necessary steps (deleting helm deployment, redeploying) with a minimum (initially 7 minutes, later 3 minutes) outage, but it required someone constantly monitoring the servers. Internal Kubernetes health-checks identified when pods stopped serving traffic, but as the problem manifested in a failure to write to the file system, new pods could not complete their initialisation and so could not successfully start to replace the failing pods.
During the weekend of 27th/28th of April, Ray identified that the issue was caused by the NFS persistent volumes that had been introduced April 4th to store wordfence application firewall rules between pods and deployments. A locust cluster was used to provide continual load testing of requests to a test site, which did not fail.
During Monday 29th of April, the solution was applied to all websites.
Sites affected
| Website | Number of outages | Total time (minutes) front end unavailable | Total time (minutes) back end unavailable |
| Belgium | 3 | 7 | 30 |
| Brasil | 1 | 25 | 40 |
| Canada | 3 | 10 | 45 |
| Chile | 1 | 480 (8 hours) | 480 (8 hours) |
| Hungary | 2 | 15 | 30 |
| India | 2 | 240 (6 hours) | 300 (5 hours) |
| Indonesia | 1 | 20 | 40 |
| International | 3 | 36 | 180 (3 hours) |
| Mena | 1 | 10 | 25 |
| New Zealand | 1 | 8 | 20 |
| Sweden | 1 | 3 | 12 |